

1. 概述
在《Java 核心技术》中第一章就提到了 码点和代码单元,但是这里讲述的懵懂;这里专门做了个专题解释;
2. Unicode 编码
在各国都有自己的编码,但是世界总是趋于统一,不然不方便;于是一个万国码出来了;即 Unicode 编码,又称为统一码;Unicode 是一种字符编码系统;为所有语言的字符提供一个唯一的数字编码;Unicode 包含几乎所有字符,常见有 UTF-8、UTF-16、UTF-32;Java 中,字符的存储和表示也是遵循 Unicode 标准;Java 采用 UTF-16 作为字符的编码;
3. Java 采用 Unicode 编码;
在 Java 中,char 和 String 类型,都是采用 UTF-16 编码进行表示字符;而 UTF-16 是一种变长编码方式;用 16 位即 2 字节来表示一个字符,但是对于一些 Unicode 码点超过基本多文种平面(BMP,范围为 U+0000 到 U+FFFF )的字符,UTF-16 采用 代理对,即两个 16 位代码单元来表示一个字符;
4. 码点与代码单元
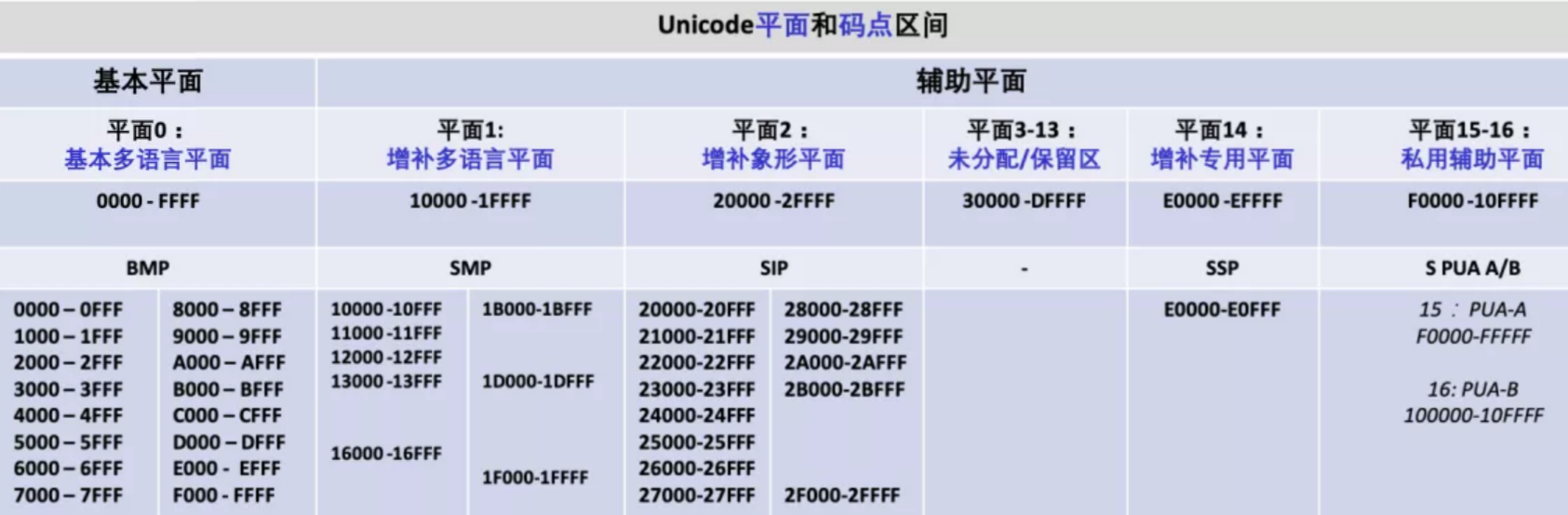
- 码点 ( code point ):指的是一个编码表中某个字符对应的代码值;
Unicode码点可以分为 17 个代码平面(code plane);其中,第一个代码平面称为基本多语言平面 (basic multilingual plane),包括码点从U+0000到U+FFFF的“经典”Unicode代码;其余 16 个平面的码点从U+10000到U+10FFFF,包括辅助字符 (supplementary character); - 代码单元( Code Unit ): 指的是 字符在编码时候,字符编码存储的单位,可能一个编码是存储为一个,也可能是两个,四个;
5. Java 中的示例
public class Test {
public static void main(String[] args) {
String str = "🤖";
System.out.println(str); //🤖
System.out.println(str.charAt(0)); //?
System.out.println(str.codePointAt(0)); // codepoint = 129302
}
}
/**
其实在我们实际遍历字符串的时候,我们想要遍历的是码点,但是实际上 charAt 之类的是遍历代码单元的;只不过在日常使用,很少遇到这种两个代码单元构成的字;但是需要注意
*/